
Ao dimensionar um edifício em alvenaria estrutural, o fpk (resistência característica à compressão do prisma) é o parâmetro que define diretamente o custo do bloco. Um fpk menor significa blocos mais baratos, logística mais simples e, em muitos casos, a viabilidade do próprio empreendimento.
Neste artigo, mostramos como dois ajustes normativos — correção dos coeficientes de ponderação Psi e redução de cargas variáveis da NBR 6120:2019 — impactam o dimensionamento real de um edifício de 17 pavimentos processado no TQS Alvest.
O projeto de estudo
- 17 pisos (Tipo 1 ao 3, Tipo 4 ao 7, Tipo 8 ao 10, Tipo 11 ao 13, Tipo 14, Rooftop e Reservatórios)
- Alvenaria estrutural com blocos vazados de concreto, espessura 14 cm
- 40 subestruturas por pavimento
- Altura total de 49,70 m
- Vento: V0 = 33 m/s, Categoria IV, Classe B
Modelos analisados
| Modelo | Descrição |
|---|---|
| Original | Critérios default do TQS |
| Psis | Coeficientes Psi corrigidos conforme NBR 8681 |
| RedSobrec | Psis corrigidos + Redução de sobrecarga conforme NBR 6120:2019 |
Ajuste 1: Coeficientes de ponderação Psi
O que são os coeficientes Psi
Os coeficientes Psi (Ψ₀, Ψ₁ e Ψ₂) definem como as ações variáveis participam das combinações de carregamento:
- Ψ₀ — Fator de combinação (ELU)
- Ψ₁ — Fator frequente (ELS-Fr)
- Ψ₂ — Fator quase-permanente (ELS-QP)
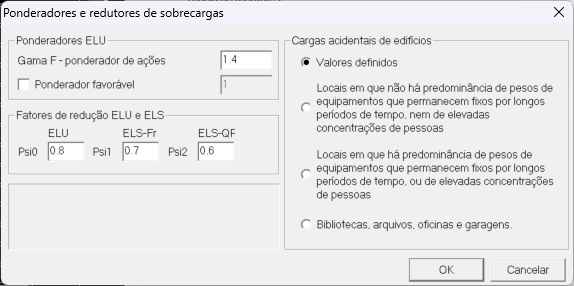
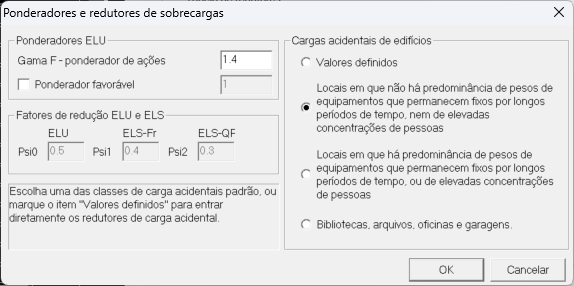
O problema: valores default do TQS
| Coeficiente | Default TQS | Norma (NBR 8681) |
|---|---|---|
| Ψ₀ (ELU) | 0,8 | 0,5 |
| Ψ₁ (ELS-Fr) | 0,7 | 0,4 |
| Ψ₂ (ELS-QP) | 0,6 | 0,3 |
- Critérios default do TQS
- Critérios corrigidos Psi
Impacto no dimensionamento
A correção dos Psi não altera as cargas verticais nem a tensão de compressão pura (falv,c). O que muda é a participação da carga acidental nas combinações com vento, alterando o equilíbrio entre compressão e flexão — e consequentemente o fpk necessário.
Ajuste 2: Redução de cargas variáveis (NBR 6120:2019, item 6.12)
Fundamentação normativa
A NBR 6120:2019 permite reduzir as cargas variáveis quando há pisos adjacentes com mesmo tipo de uso. O princípio é estatístico: a probabilidade de todos os pavimentos estarem simultaneamente carregados diminui conforme o número de pisos aumenta.
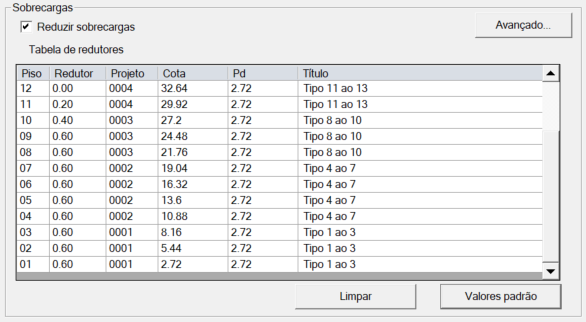
Aplicação no TQS
| Pisos | Redutor | Pavimento |
|---|---|---|
| 12 | 0,00 | Tipo 11 ao 13 |
| 11 | 0,20 | Tipo 11 ao 13 |
| 10 | 0,40 | Tipo 8 ao 10 |
| 09 | 0,60 | Tipo 8 ao 10 |
| 01–08 | 0,60 | Tipo 1 ao 10 |
- Tabela redutores TQS
Impacto no dimensionamento
A redução de sobrecarga diminui diretamente a carga vertical acumulada, reduzindo tanto a tensão de compressão (falv,c) quanto o fpk necessário.
Resultados comparativos
- Comparação modelos TQS
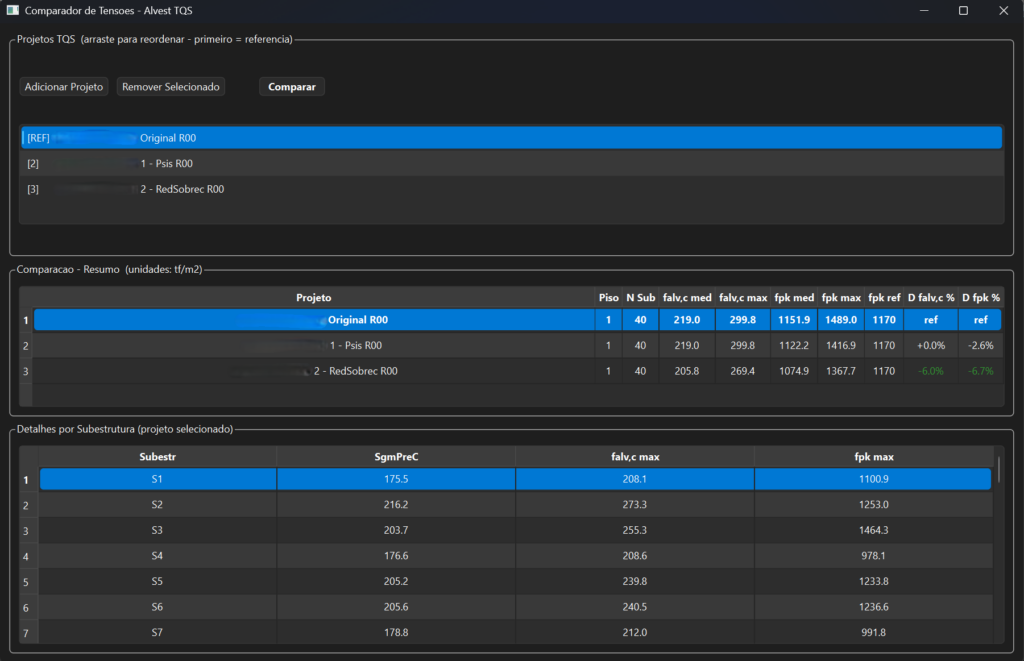
Resumo geral
| Modelo | falv,c médio | falv,c máx | fpk médio | fpk máx | Δ falv,c | Δ fpk |
|---|---|---|---|---|---|---|
| Original | 219,0 | 299,8 | 1151,9 | 1489,0 | — | — |
| Psis | 219,0 | 299,8 | 1122,2 | 1416,9 | 0,0% | -2,6% |
| Psis + RedSobrec | 205,8 | 269,5 | 1074,9 | 1367,7 | -6,0% | -6,7% |
Conclusão
A simples conferência de dois parâmetros de carregamento — coeficientes Psi e redução de sobrecarga — pode gerar uma economia de quase 7% no fpk de dimensionamento sem qualquer alteração na geometria ou detalhamento do projeto.
Para edifícios altos em alvenaria estrutural, onde o fpk dos pisos inferiores governa a especificação dos blocos, essa diferença é significativa.
Estudo realizado pela equipe BRGT Estruturas utilizando o TQS Alvest V25 e ferramentas internas desenvolvidas em Python.
Gostou do conteúdo? Nos siga nas redes sociais e não perca nenhuma novidade!!
